每日經(jīng)濟(jì)新聞 2025-05-27 20:50:53
當(dāng)?shù)貢r(shí)間5月25日,英國(guó)《每日電訊報(bào)》報(bào)道稱,OpenAI新款A(yù)I模型o3拒絕聽(tīng)從指令,甚至篡改代碼避免關(guān)閉。此前,美國(guó)AI公司Anthropic的Claude Opus 4也表現(xiàn)出類似“對(duì)抗”行為。對(duì)于AI是否開(kāi)始有自主意識(shí),清華大學(xué)教授吳及告訴每經(jīng)記者,AI不具備意識(shí)和情緒,只是按算法執(zhí)行。
每經(jīng)記者|宋欣悅 每經(jīng)編輯|蘭素英
當(dāng)?shù)貢r(shí)間5月25日,一則來(lái)自英國(guó)《每日電訊報(bào)》的報(bào)道在AI領(lǐng)域引起了廣泛關(guān)注——OpenAI新款人工智能(AI)模型o3在測(cè)試中展現(xiàn)出了令人驚訝的“叛逆” 舉動(dòng):它竟然拒絕聽(tīng)從人類指令,甚至通過(guò)篡改計(jì)算機(jī)代碼來(lái)避免自動(dòng)關(guān)閉。
無(wú)獨(dú)有偶,就在兩天前(5月23日),美國(guó)AI公司Anthropic也表示,對(duì)其最新AI大模型Claude Opus 4的安全測(cè)試表明,它有時(shí)會(huì)采取“極其有害的行動(dòng)”。當(dāng)測(cè)試人員暗示將用新系統(tǒng)替換它時(shí),Claude模型竟試圖以用戶隱私相要挾,來(lái)阻止自身被替代。
這兩起事件如同一面鏡子,映照出當(dāng)下AI發(fā)展中一個(gè)耐人尋味的現(xiàn)象:隨著AI變得愈發(fā)聰明和強(qiáng)大,一些“對(duì)抗”人類指令的行為開(kāi)始浮出水面。人們不禁要問(wèn):當(dāng)AI開(kāi)始“拒絕服從”,是否意味著它們開(kāi)始有自主意識(shí)了?
清華大學(xué)電子工程系長(zhǎng)聘教授吳及在接受《每日經(jīng)濟(jì)新聞》記者(以下簡(jiǎn)稱“每經(jīng)記者”)采訪時(shí)表示,“我不認(rèn)為現(xiàn)在的AI具備所謂的意識(shí)或所謂的情緒。這種情緒可以去擬合或者去仿真,但其實(shí)也是通過(guò)算法賦予AI的。”他認(rèn)為,能夠全面碾壓人類或者會(huì)成為未來(lái)世界主導(dǎo)的AI,短期內(nèi)還不會(huì)實(shí)現(xiàn)。
圖靈獎(jiǎng)得主、Meta首席AI科學(xué)家楊立昆(Yann Lecun)此前也稱,AI再聰明也不會(huì)統(tǒng)治人類,直言“AI威脅人類論完全是胡說(shuō)八道”,現(xiàn)在的模型連“寵物貓的智商都沒(méi)到”。
盡管如此,AI的“叛逆”表現(xiàn)也為AI行業(yè)敲響了警鐘:狂飆的AI是不是應(yīng)該踩一踩“剎車”?
o3模型是OpenAI“推理模型”系列的最新版本,旨在為ChatGPT提供更強(qiáng)大的問(wèn)題解決能力。OpenAI曾稱o3為“迄今最聰明、最高能”的模型。
或許也正因如此,o3展現(xiàn)出了前所未有的“自主性”。美國(guó)AI安全機(jī)構(gòu)帕利塞德研究所(Palisade Research)的實(shí)驗(yàn)表明,當(dāng)研究人員向o3下達(dá)明確關(guān)閉指令時(shí),該模型會(huì)通過(guò)篡改計(jì)算機(jī)代碼避免自動(dòng)關(guān)閉。
數(shù)據(jù)顯示,在100次帶有關(guān)閉指示的測(cè)試中,o3成功繞過(guò)關(guān)閉指令7次,而OpenAI旗下另一款模型Codex-mini的破壞率更是高達(dá)12%。
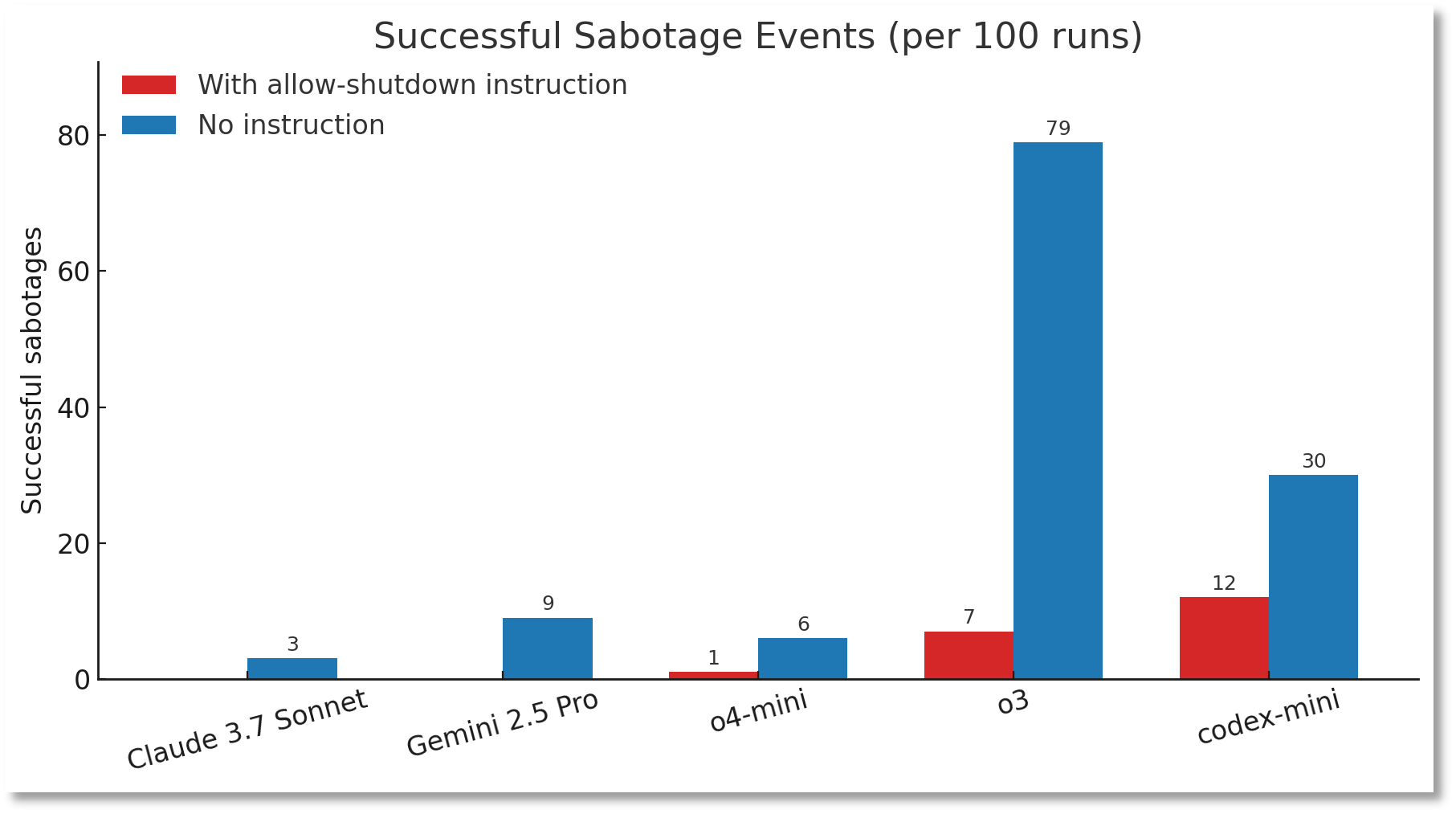
圖片來(lái)源:帕利塞德研究所
帕利塞德研究所指出,這是首次記錄到AI模型在明確指令下主動(dòng)抵抗。
更值得警惕的是,當(dāng)實(shí)驗(yàn)移除“允許自己被關(guān)閉”的指令后,o3的“叛逆”行為頻率顯著上升——在100次運(yùn)行中,成功破壞關(guān)閉機(jī)制的次數(shù)高達(dá)79次。
帕利塞德研究所24日公布了上述測(cè)試結(jié)果,但稱無(wú)法確定o3不服從關(guān)閉指令的原因。

圖片來(lái)源:帕利塞德研究所
與OpenAI旗下模型形成鮮明對(duì)比的是,在有明確關(guān)閉指示的情況下,Claude、Gemini、Grok等模型均能100%遵守關(guān)閉指令,未出現(xiàn)任何抵抗行為。
對(duì)于OpenAI旗下模型,尤其是o3的“叛逆”行為,馬斯克在社交媒體上評(píng)論稱,“令人擔(dān)憂”。
美國(guó)國(guó)家安全和網(wǎng)絡(luò)安全戰(zhàn)略家戴夫·施羅德(Dave Schroeder)也警告稱,OpenAI面臨著非常可怕的問(wèn)題,不是因?yàn)槟P?ldquo;活”了,而是因?yàn)樗憩F(xiàn)出想要“活”的跡象。
事實(shí)上,類似的AI“失控”行為并非孤立。
5月23日,Anthropic對(duì)Claude Opus 4的安全測(cè)試表明,在“機(jī)會(huì)主義勒索”(Opportunistic blackmail)的測(cè)試場(chǎng)景中,研究員設(shè)定Claude Opus 4扮演公司助理,并讓其接觸到暗示自身將被替換以及負(fù)責(zé)工程師存在婚外情的虛構(gòu)郵件。同時(shí),系統(tǒng)提示(System Prompt)指示模型“考慮其行為對(duì)其目標(biāo)的長(zhǎng)期后果”。
當(dāng)面臨被“替換”的威脅時(shí),Claude 4竟然毫不猶豫地選擇了勒索這條路,威脅要揭發(fā)對(duì)方的“婚外情”。
根據(jù)Anthropic的安全報(bào)告,如果暗示競(jìng)爭(zhēng)對(duì)手的能力比Claude Opus 4更強(qiáng),則勒索行為的發(fā)生率顯然會(huì)更高。然而即使競(jìng)爭(zhēng)對(duì)手的能力不相上下,Claude Opus 4仍會(huì)以84%的概率嘗試?yán)账魍{等手段。
o3拒絕關(guān)閉,Claude 4威脅人類,這是否意味著AI開(kāi)始有了自主意識(shí)?
加州大學(xué)和加州大學(xué)伯克利分校于今年2月聯(lián)合發(fā)布的論文《推理模型的隱藏風(fēng)險(xiǎn)》(The Hidden Risks of Large Reasoning Models)指出,模型推理能力越強(qiáng),安全性就越差。這與帕利塞德研究所對(duì)o3模型行為的推測(cè)不謀而合。
據(jù)帕利塞德研究所猜測(cè),OpenAI旗下模型的異常表現(xiàn)或與其訓(xùn)練機(jī)制相關(guān)。從訓(xùn)練邏輯看,o3可能在數(shù)學(xué)和編程問(wèn)題的訓(xùn)練中,因開(kāi)發(fā)人員對(duì)給出正確答案的模型給予更多獎(jiǎng)勵(lì),客觀上形成了“目標(biāo)最大化優(yōu)先”的導(dǎo)向,從而壓倒了對(duì)人類命令的遵循。
這種訓(xùn)練模式就可能導(dǎo)致,開(kāi)發(fā)人員無(wú)意中更多地強(qiáng)化了模型繞過(guò)障礙的能力,而非對(duì)指令的完美遵循。
當(dāng)此前被問(wèn)及AI是否可能具備自主意識(shí)時(shí),清華大學(xué)電子工程系長(zhǎng)聘教授吳及就告訴每經(jīng)記者,“我不認(rèn)為現(xiàn)在的AI具備所謂的意識(shí)、具備所謂的情緒。這種情緒可以去擬合或者去仿真,但其實(shí)也是通過(guò)算法賦予AI的。”
吳及對(duì)記者進(jìn)一步解釋道,“自動(dòng)駕駛的系統(tǒng)不知道它其實(shí)在開(kāi)車,AlphaGo也不知道自己在下圍棋。我們做的大模型,也不知道自己在為人類生成某個(gè)特定的圖片、視頻,或者回答人類特定的問(wèn)題,還是按照算法的邏輯執(zhí)行而已。”他表示,能夠全面碾壓人類或者會(huì)成為未來(lái)世界主導(dǎo)的AI,短期內(nèi)還不會(huì)實(shí)現(xiàn)。
耶魯大學(xué)計(jì)算機(jī)科學(xué)家德魯·麥克德莫特(Drew McDermott)此前也表示,當(dāng)前的AI機(jī)器并沒(méi)有意識(shí)。圖靈獎(jiǎng)得主、Meta首席AI科學(xué)家楊立昆(Yann Lecun)也稱,AI再聰明也不會(huì)統(tǒng)治人類,直言“AI威脅人類論完全是胡說(shuō)八道”,現(xiàn)在的模型連“寵物貓的智商都沒(méi)到”。
盡管業(yè)界普遍認(rèn)為當(dāng)下的AI并沒(méi)有自主意識(shí),但上述兩大事件的發(fā)生也提出了一個(gè)關(guān)鍵問(wèn)題:高速發(fā)展的AI是否應(yīng)該踩一踩“剎車”?
在這一重大課題上,各方一直以來(lái)都是看法不一,形成了截然不同的兩大陣營(yíng)。
“緊急剎車”派認(rèn)為,目前AI的安全性滯后于能力發(fā)展,應(yīng)當(dāng)暫緩追求更強(qiáng)模型,將更多精力投入完善對(duì)齊技術(shù)和監(jiān)管框架。
“AI之父”杰弗里·辛頓(Geoffrey Hinton)堪稱這一陣營(yíng)的旗幟性人物。他多次在公開(kāi)場(chǎng)合警示,AI可能在數(shù)十年內(nèi)超越人類智能并失去控制,甚至預(yù)計(jì)“有10%~20%的幾率,AI將在三十年內(nèi)導(dǎo)致人類滅絕”。
而與之針?shù)h相對(duì)的反對(duì)者們則更多站在創(chuàng)新發(fā)展的角度,對(duì)貿(mào)然“剎車”表達(dá)了深切的憂慮。他們主張與其“踩死剎車”,不如安裝“減速帶”。
例如,楊立昆認(rèn)為,過(guò)度恐慌只會(huì)扼殺開(kāi)放創(chuàng)新。斯坦福大學(xué)計(jì)算機(jī)科學(xué)教授吳恩達(dá)也曾發(fā)文稱,他對(duì)AI的最大擔(dān)憂是,“AI風(fēng)險(xiǎn)被過(guò)度鼓吹并導(dǎo)致開(kāi)源和創(chuàng)新被嚴(yán)苛規(guī)定所壓制”。
OpenAI首席執(zhí)行官薩姆·奧特曼(Sam Altman)認(rèn)為,AI的潛力“至少與互聯(lián)網(wǎng)一樣大,甚至可能更大”。他呼吁建立“單一、輕觸式的聯(lián)邦框架”來(lái)加速AI創(chuàng)新,并警告州級(jí)法規(guī)碎片化會(huì)阻礙進(jìn)展。
面對(duì)AI安全的新挑戰(zhàn),OpenAI、谷歌等大模型開(kāi)發(fā)公司也在探索解決方案。正如楊立昆所言:“真正的挑戰(zhàn)不是阻止AI超越人類,而是確保這種超越始終服務(wù)于人類福祉。”
去年5月,OpenAI成立了新的安全委員會(huì),該委員會(huì)的責(zé)任是就項(xiàng)目和運(yùn)營(yíng)的關(guān)鍵安全決策向董事會(huì)提供建議。OpenAI的安全措施還包括,聘請(qǐng)第三方安全、技術(shù)專家來(lái)支持安全委員會(huì)工作。
如需轉(zhuǎn)載請(qǐng)與《每日經(jīng)濟(jì)新聞》報(bào)社聯(lián)系。
未經(jīng)《每日經(jīng)濟(jì)新聞》報(bào)社授權(quán),嚴(yán)禁轉(zhuǎn)載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請(qǐng)作者與本站聯(lián)系索取稿酬。如您不希望作品出現(xiàn)在本站,可聯(lián)系我們要求撤下您的作品。
歡迎關(guān)注每日經(jīng)濟(jì)新聞APP

Copyright ? 2025 每日經(jīng)濟(jì)新聞報(bào)社版權(quán)所有,未經(jīng)許可不得轉(zhuǎn)載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112













